Projet «Raisonnement à base d’Expériences » (RXP)
Depuis quelques années, les technologies électronique et informatique occupent une place primordiale dans le secteur automobile. En effet, les constructeurs ont commencé à intégrer de plus en plus de composants électroniques et logiciels au sein des véhicules. Le but recherché est multiple : accroître leur sécurité, leur fiabilité, leur durée de vie et leur agrément de conduite. Ce phénomène a eu pour conséquence indirecte un bouleversement profond dans le type de pannes automobiles rencontrées et dans la façon même de détecter et de réparer celles-ci.
Afin d'aider un garagiste dans sa tâche de diagnostic, la thèse entreprise a pour double ambition de concevoir un module de gestion de base d’expériences et de mettre en place un langage formel de communication permettant à plusieurs modes de raisonnement de collaborer dans un même outil logiciel : MODE (Fig. 1).
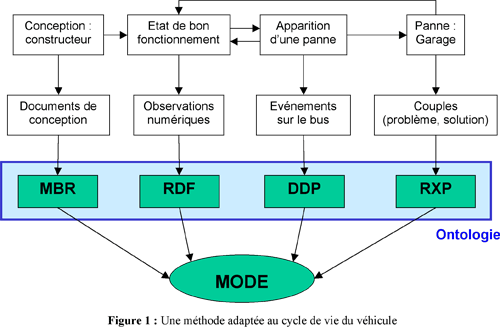
L'application sur laquelle nous nous sommes penchés en priorité (RXP) consiste à rechercher dans une base d'expérience des fiches de réparation pertinentes pour une panne sur un véhicule donné : à partir de la description en langue naturelle des symptômes, l'outil doit retrouver un ensemble de fiches structurées traitant d'un problème similaire sur le même type de véhicule. Il a été choisi d’adapter des technologies du web sémantique dans ce cadre (domaine spécialisé, documents très structurés et utilisateur ayant une tâche de diagnostic à réaliser), à savoir de s’appuyer sur un modèle de connaissances (une ontologie) pour représenter le contenu des documents et y rechercher des informations.
Un simple moteur de recherche basé sur une indexation classique par mots-clés aurait pu suffire mais, en l'absence d'une modélisation des connaissances du diagnostic automobile, il aurait été impossible de raisonner sur les objets du domaine (e.g. la présence d'un symptôme peut entraîner celle d'un autre). De plus, l’utilisation d’un modèle de connaissances permet de s’affranchir du problème du multilinguisme. En effet, on part de l’hypothèse selon laquelle, dans un domaine technique spécifique, on peut retrouver les mêmes concepts et les mêmes relations les reliant, indifféremment de la langue utilisée. Un modèle de connaissances permet donc de représenter de façon unique une structure de notions consensuelles (concepts) dont les manifestations linguistiques (termes) varient selon la langue employée.
Pendant la première année de thèse, nous avons donc travaillé sur une formalisation des connaissances du domaine : nous avons choisi l’ontologie comme type de modélisation et nous avons construit celle-ci par analyse d’un corpus du domaine constitué par nos soins (fig. 2) et de connaissances d’experts.
|

Figure 2 : Construction d’ontologie à partir de textes |
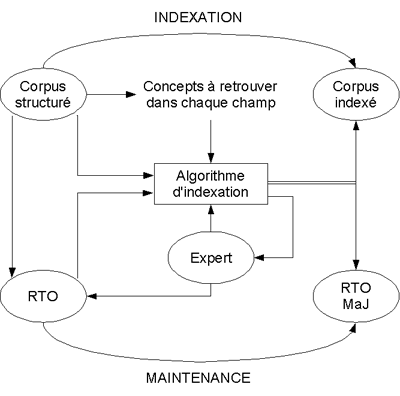 Figure 3 : Indexation de fiches avec maintenance d’ontologie Figure 3 : Indexation de fiches avec maintenance d’ontologie
|
Nous avons ensuite concentré nos efforts sur la mise au point d’un mécanisme d’indexation conceptuelle des fiches et d’une chaîne de traitement (notamment avec des outils de Traitement Automatique du Langage) visant à maintenir le modèle de connaissances lors de l’ajout de nouvelles fiches dans la base d’expérience. Une fois cette chaîne mise en place, il sera intéressant d’évaluer l’efficacité du système de recherche d’information ainsi construit par rapport à des systèmes plus classiques (du type moteurs de recherche) n’utilisant pas de modèle de connaissances du domaine.
L’ontologie sera par la suite employée pour une collaboration avec et entre les autres méthodes de raisonnement mises en oeuvre au sein du logiciel d’aide au diagnostic, à savoir la reconnaissance de formes (RdF), le diagnostic distribué préventif (DDP) et le raisonnement à base de modèles (MBR). En effet, celles-ci manipulent en commun certains objets du domaine.
L’originalité et l’intérêt de ce sujet résident d’abord dans le choix de réaliser un outil de recherche d’information basé non sur une indexation classique mais sur une indexation conceptuelle des ressources. De plus, la structuration des fiches de réparation à rapprocher de la démarche classique d’un garagiste (modèle de la tâche) est prise en compte dans la modélisation des connaissances. Enfin, face à la nécessité de faire intervenir le moins possible un opérateur humain (taille des corpus, coût de l’expertise), un processus semi-automatique de mise à jour de la base d’expériences a été imaginé : il permet de réaliser en parallèle une indexation de fiches et une maintenance de l’ontologie. |
CHERCHEURS CONCERNES :
- Axel Reymonet, thèse CIFRE, ACTIA et IRIT-CSC
- Jérôme Thomas, ingénieur ACTIA
- Nathalie Aussenac-Gilles, Chargé de recherche CNRS, IRIT-CSC
- Jean-Luc Soubie, Ingénieur de recherche, responsable de l’équipe CSC, IRIT.
MOTS-CLES :
Construction d’ontologie à partir de textes, peuplement d’ontologies, indexation conceptuelle, annotation semi-automatique, recherche d’information
KEYWORDS :
Ontology engineering from texts, ontology population, semantic indexing, semi-automatic annotation, information retrieval
|


