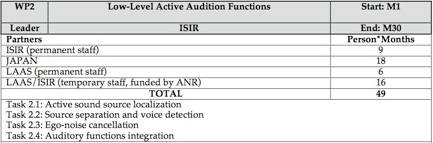
WP2
Low-Level Active Audition Functions
WP2
Low-Level Active Audition Functions

Description :
This workpackage aims at providing low-level auditory functions, such as sound source localization, detection and extraction, relying on active strategies for perception. It will exploit the auditory cues extracted from a binaural auditive perception (see WP1), as well as multimodal information coming from proprioception or other exteroceptive modalities defined in WP3.1. This work will then be integrated into a common software framework developed by the JAPAN team named HARK, in the form of modules for robot audition for the FlowDesigner software..
Keywords :
Self-noise reduction, active perception, sound source localization, detection and extraction, software integration
The first problem to be addressed is sound source localization in the context of binaural perception. However, as per [Kim2009], two transducers do not have enough performance to cope with noisy environments or sound processing over the entire azimuth range. For example, it is hard for a robot to distinguish whether sound sources are being generated from its front or rear due to the symmetry of its head and ear locations. Nevertheless, the number of works trying to reproduce the human capability to localize sound sources from only two ears is growing, such capabilities being now considered as essential for human- robot interaction. So, in task 2.1, we propose to localize broadband sound sources through static or dynamic strategies, while exploiting additional exteroceptive data like vision.
First, the required auditory cues for localization will be defined and delivered to Task 1.2. Generally, these cues include at least Interaural Level Difference (ILD), Interaural Phase Difference (IPD) and Interaural Time Difference (ITD), but other cues such as Monaural Spectral Notches, or Normalized Spectral Power may prove useful.
Next, the localization of one source will be assessed by exploiting the defined auditory cues through the theoretical modeling of the propagation developed in Task 1.1. Similar models have been proposed in the literature, such as the
Task 2.1 : Active Sound Source Localization
Since the humanoid robot faces a mixture of sounds caused by interfering talks, environment sounds, and other noises, known or unknown, in real-world environments, each meaningful sound source should be separated. Currently, most of sound source separation methods, except Independent Component Analysis (ICA) based ones, assume the direction of sound source obtained by sound source localization. This combination of sound source localization and sound source separation works well. For example, [Nakadai2008] develop the HARK robot audition system combines MUSIC (Multiple Signal Classification) or steered beamformer as a sound source localization algorithm, and GSS (Geometrical Source Separation) or beamformers as a sound source separation algorithm. They demonstrate three talkers’ simultaneous speech recognition as a task of waitress and as a judge of “rock- scissors-paper” game by voiced speeches. The HARK system, however, assumes that the separated sound is a voiced speech. In real-world applications, this assumption may not hold.
The detection of speech activity called “voice activity detection” (VAD) is mandatory for speech recognition and higher-lever interactions. VAD is also expected to improve the performance of CASA functions, that is, sound source localization, sound source separation, and automatic speech recognition (ASR) of separated sounds. VAD and sound source separation interact each other. If we estimate VAD precisely, we can separate voiced signals better. In addition, if we separate voiced signals well, we can estimate VAD more precisely. Some people improve the performance of VAD by using ASR, and ASR improves its performance by using VAD. In other words, VAD is connected severely to sound source separation and ASR.
In fact, if the separated sound is voiced speech, the issues in the improvement of automatic speech recognition (ASR) systems are voice activity detection (VAD) [Lu2002], noise suppression, and speaker adaptation. VAD is quite useful not only for automatic speech recognition but also for speech coding and speaker diarization. Since VAD and ASR are like two sides of a coin, the quality of VAD improves the performance of ASR and vice versa.
For binaural audition, Kim et al [Kim2009] apply motion theory to robot audition to improve the poor performance due to front-back ambiguities. Motions are critical for overcoming the ambiguity and sparseness of information obtained by two microphones. To realize this, they first designed a sound source localization system integrated with cross-power spectrum phase (CSP) analysis and an EM algorithm. The CSP of sound signals obtained with only two microphones was used to localize the sound source without having to measure impulse response data. The EM algorithm helped the system to cope with several moving sound sources and reduce localization errors. We then proposed a way of constructing a database for moving sounds to evaluate binaural sound source localization. We evaluated our sound localization method using artificial moving sounds and confirmed that it could effectively localize moving sounds slower than 1.125 rad/sec. Consequently, we solved the problem of distinguishing whether sounds were coming from the front or rear by rotating and/or tipping the robot’s head that was equipped with only two microphones. Our system was applied to a humanoid robot called SIG2, and they confirmed its ability to localize sounds over the entire azimuth range.
The BINAAHR project focuses on the design and implementation of VAD algorithm from the viewpoint of integration with sound source separation. Since the VAD attacks the segmentation problem of a mixture of sounds, it will contribute the improvement of sound source localization and sound source separation, and thus indirectly that of automatic speech recognition of automatic sound source recognition. In other words, the VAD algorithm depends on either the property of sound source or simple acoustic features. The model- based approach will incorporate psychological and psychophysical observation as well as brain science observation.
Task 2.2 : Source Separation and Voice Detection
One type of proprioceptive measurements is of particular interest. It concerns the quantification of motion-induced acoustic noise, which blurs the auditory perception of the environment. Such a problematic is fundamental for active auditive perception, and strongly influences the conception of the acoustic sensor. For example, the artificial ears proposed in [Rodemann2008] are designed so as to attenuate signals from the back of the head, and more specifically from fan noise coming from the embedded hardware. In addition, due to its ego- motion noise, the sound localization process must be interrupted when the speed of the head exceeds a certain value.
So far, the Robotics community has seldom addressed this problematic. One solution was proposed in [Nakadai2000] on the basis of adaptive filters and additional microphones placed near the motors inside the cover of the robot. To our knowledge, this work constitutes one of the few studies, which deal with self-noise removal. So, Task 2.3 will provide new methods to noise cancellation in the context of active binaural audition. One line of research is the characterization of the noise sources (motors, fans, etc.) originating from the robotic platform from audio signals captured by dedicated microphones. The main idea is then the identification of some noise signatures (frequency response of the motor, fundamental frequency for fan, etc.), which could be of interest for their cancellation in the perceived binaural signals. Such a study could be leaded:
-from a statistical viewpoint, where self-noise is assimilated to an additive noise with specific statistical properties which will be identified,
-from a higher-level viewpoint, where self-noise modifies the extracted auditory cues which will be then used to generate auditory functions.
Task 2.3 : Ego-Noise Cancellation
Epipolar Auditive Geometry [Nakadai2001]. While they are generally nonlinear, their purpose is to link the extracted auditory cues to the position of the source. These models can also be identified through experimental measurements, leading to the well-known Head Related Transfer Function (HRTF). But identifying the HRTF returns to the determination of an impulse response in anechoic environment, which requires heavy experimental conditions. Consequently, the HRTF-based localization methods will not be considered here. Instead, approaches combining sound cues with proprioception and vision will be investigated. Indeed, the complementarity and redundancy of the exploited multimodal data may dramatically improve the localization accuracy and robustness.
-In the same vein as [Hornstein2006], static maps combining audition, proprioception and vision will be generated, e.g. through neural or evolutionist learning methods. The aim is to check if a generalization to various acoustic environments can be performed by the proposed learning method. In case this procedure fails, alternative methods will be envisioned, rooted on the identification of nonlinear uncertain static models.
-The integration of the motion of the binaural platform will be considered as well. The possibility to complement the “stop and listen” approach of [Kneip2008], which copes with the incremental source localization from auditory data gathered at various positions a two-microphone dipole, will be investigated in order to take account of the presence of the head. Then, source localization algorithms from a continuously moving head will be developed. The aim is to spatio-temporally fuse the auditory cues predicted on the basis of the sensor dynamics with the information held in the audio measurements. Filtering strategies will be evaluated, in a stochastic [Brèthes2008] or uncertain deterministic context [Bellot2003], [Durola2008]. Note that this approach is distinct from existing approaches which consist in particle filter based post-processing on the top of localization, in that the aim is to perform the
-fusion right at the localization level (and not in an upper tracking level).
Task 2.4 : Auditory Functions Integration
This task is an integration task where all the needed software developments of WP2 will be included. The proposed software solution is based on the all-new open-source software called HARK (HRI-JP Audition for Robots with Kyoto University) and developed by Prof. Okuno’s team [Nakadai2008]. The objective of this software is to provide
-elementary auditory functions included in a total robot audition system,
-a firm framework for researchers who are not familiar with robot audition.
-
HARK is based on a complete module set to build a real-time robot audition system without any complicated implementation. Thanks to its module-based architecture, it can be applied to various types of robots and hardware configurations. For the moment, sound source localization, separation and automatic missing feature mask generation modules are implemented, most of them in the context of array processing. HARK also exploit the open- source FlowDesigner software to allow end-users to create reusable modules and connect them together using a standardized mechanism to create a network of modules. It is also proposed to exploit the library coded in Task 1.3 providing the auditory cues extraction. So, such a modular framework will ease the collaboration between each partners of the project by allowing each team to work on their own auditory function module.


Back