

Tina V1 Proof of concept (APL prototypes, 1981-1983)
Contents
TINA development started by 1981, in language APL (APL\360 version) as a follow-up of several Petri Net analysis tools [28][29][25]. Concerning Time Petri Nets, the tool introduced the state classes method presented in the sequel in the works [22][26][27][1][23][2], notably. The early accounts of the tool presented here, retrospectively referred to as TINA V1, are provided for historical purposes only. For any actual verification task, please use instead the latest release of the TINA toolbox.
Provided here are :
Scans of APL workspace TPN5 (Time Petri Net analysis library)
-
tpn5.pdf is a series of pictures of the APL source code of the
sole TPN analysis workspace (named TPN5) that could be preserved
in full, dated 1983. Workspace (read library) TPN5 contains the
APL code for computing state classes, plus test examples. It was
part of a more ambitious environment also providing libraries for
structural analysis and reductions of Petri nets started by 1977,
but not all these parts could be recovered.
Assets: scans of TPN5 contents [tgz].
V1.0/ibm -- IBM APL TPN5 sources
-
V1.0/ibm is a hopefully exact manual transcription of workspace
TPN5 done in 2023. So, unless you have access to an IBM 370
mainframe with APL installed, or to an IBM 5100 workstation
providing APL or to a PC of the era with a compatible APL
installed, you'd better consider the ports below.
Transcription notes:
-
- the transcription produces a unicode textual file in the
original IBM APL character set (with underlined uppercase
letters);
- The spaces between APL symbols and alphanumeric characters
are, except in character strings, non significant; some may
have been added or removed, for readability;
- For some unknown reason, the printer that produced the TPN5
listing printed the APL character ≥ by a dollar sign, which
is not in the APL character set. Dollar signs are thus
transcribed ≥ .
Assets: exact transcription of workspace TPN5
Usage:
-
Provided for historical purposes only. The files in the assets
containing APL sources can be read by any text editor
supporting unicode. Except if you want to edit them (in APL),
no installation of an APL font is required.
V1.0/gnuapl -- GNU APL port
-
This is a straightforward port of V1.0/ibm code on GNU/APL, plus some
obvious bug fixes (that were probably fixed in subsequent APL
versions), some features made optional and with addition of a
toplevel (script tina) in the style of the current TINA V3.8.0
tina tool replacing the lost one.
Porting notes
-
The V1.0/ibmapl sources are translated as follows:
- IBM APL\360 had no lower case letters, but provided
underlined upper case letters. Conversely, GNU APL provides
lower case letters but not underlined characters. So, upper
case letters are preserved, but underlined uppercase letters
are transcribed into lowercase letters;
- GNU APL does not allow a function and a variable to bear the
same name. The case happens notably for identifier
"p". For this reason, functions names in lowercase are
suffixed by an underscore (e.g. be becomes be_);
- Finally, TPN5 provided a user-defined function (LISTFNS) to
print the source code of all functions and variables in a
workspace. This function had to be rewritten to work in GNU
APL, but it is no more needed thanks to the GNU APL system
function ")dump" that saves the contents of a workspace in
a file in source form.
Bug fixes and improvements:
-
- "Legacy net format": The example nets in library TPN5 were
described by functions, in a style close to the current .net
format (see e.g. functions ABP and IFIP83). This way, we
could use the function editor coming with the APL
environment to edit nets. These "net functions" were not
executable but they could be read as character matrices and
their contents parsed as nets. That was allowed in APL\360
but GNU APL is less permissive on function syntax and
rejects those describing nets this way. This could be
easily fixed by prefixing and suffixing the lines of all
"net functions" by a single quote. The quotes make them
strings of characters and the functions accepted. The
parsing functions for nets in that format (retrospectively
referred to as the "legacy" format) have been updated
accordingly. An alternative format has also been defined,
in which the functions describing nets directly build their
APL representation (see details in the howto file in
distributions below);
- When computing markings, TPN5 checked on the fly the
boundedness property, using the Karp&Miller condition for
Petri nets and a range of sufficient conditions for Time
Petri nets (boundedness is undecidable for the latter). To
make that option behave similarly to that provided by the
latest tina version, checking boundedness on the fly can now
be disabled, by setting variable boundednesstest to 0.
Functions SETBOUNDEDNESSTEST and BOUNDEDTEST have been
updated accordingly. Also removed variable
L∆BOUNDEDTESTLEVEL, that looks like a duplicate of
L∆BOUNDEDNESSTEST.
- Infinite latest firing times (lft's) were not properly
handled by TPN5: canonization of firing domains was slightly
off and could distinguish equal domains. A minor fix of
function SUBSTITUTE solved this issue (see lines
8-11).
- The original TPN5 computed state classes like current tina
does with option -Wm, that is by associating a time interval
with every enabled instance of a transition. To ease
comparisons with the current tina, a MULTI option has been
added, affecting essentially functions TIR and TS2. If set,
then tina behaves like the original. Setting MULTI also
checks finite enabledness of transitions and aborts tina if
it is not finite. If not set then tina behaves like current
tina with option -W (the usual state classes construction,
without multi-enabledness);
- Early tina versions used a slightly different canonical form
for firing domains (DBMs): domains were time shifted towards
the origin of the minimum amount so that some enabled
transition (if any) was firable at time 0, and the shift
value was recorded in the class graph. Still for enabling
comparisons with the current tina, this translation of
classes is now made optional, thanks to a SHIFT variable.
Functions RECALE, PRINTNODE have been updated
accordingly;
- Finally, it is now required in net formats that at least one
place and one transition are provided. Function PRINTCLASS
has also been updated to cope with the case when no
transition is enabled.
tina toplevel
-
The original APL tina toplevel was lost, but a new one could
be easily built on top of the ported TPN5 library, in about
200 lines of APL. Further, since GNU APL features a script
option, that toplevel could be encapsulated in a shell script
(named tina) for batch operation. Some example calls are
shown below.
Assets:
Usage
-
The first requirement is to install GNU APL. Packages are
available for common Linux distributions; binary distributions
are available for Windows (on top of cygwin); and brew can
install it on recent macos versions. You can also compile it
yourself from its source code. It should be noted that no
installation of an APL character set or keyboard is necessary
for running tina-1.0. This should only be necessary for
editing the apl sources, if desired; a convenient font and
virtual keyboard are available on the Dyalog APL site, home of
another reputable implementation of APL and environment, free
for non-commercial purposes.
Folder scripts in the above archive contains the GNU APL port of the "TPN5" library of 1983, presented in two files:
-
- TPN.apl: the analysis library (computation of state classes,
strong connected components, etc). Number of functions and
variables in it are not used by the tina application since,
as already said, TPN5 was only a part of a broader
environment which could not be reconstructed. Also some
functions have been omitted since they are already provided
by GNU APL.
- nets-libs.apl: a library of examples including those found in TPN5. All declared nets are found in folder nets in .ndr or .net format.
To which are added:
-
- tools.apl: the tina toplevels (batch and interactive
versions), defined on top of TPN.apl and some utility
functions;
- tina.apl: the "main" of the tina application; loads the
apl sources, analyzes the command line and then calls the
batch version of the toplevel with the specified
options;
- tina: a shell script calling the main function in tina.apl
and filtering the results.
Still in this folder, file howto explains the usage of script tina and also how to add new nets to library nets-lib.apl and how to create them in tool nd.
An illustration:
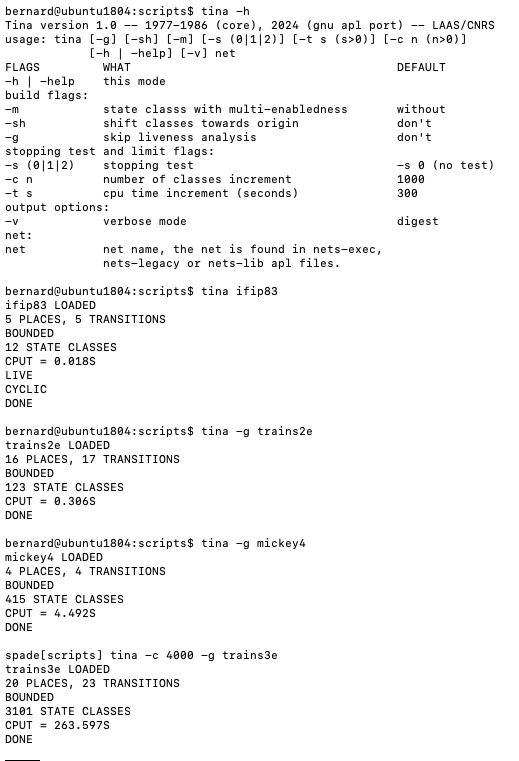
V1.1/gnuapl -- V1.0 + some simple optimizations
Benchmark for tina on 3 typical use cases:
-
l6000: many markings, no time
trains3e: typical (mixed) tpn, most transitions timed, a few not
mickey5: pure firing domains, all state classes have the same marking
On these examples, tina V1.0 takes respectively (in seconds, on a 3.2GHz Intel i7 Mac mini, with GNU APL 1.9):
-
l6000: 300 (6000 markings)
trains3e: 186 (3101 classes)
mickey5: 300 (4321 classes)
As often the case with interpreted languages, cpu times may significantly vary accross different calls, say by +/- 10%.
After some experiments, an important bottleneck could be identified in function FIND in TPN.apl, that seeks for a state class with a given marking and firing domaim. Function REDUC in it, removing duplicates in a set was found very costly in many cases. A first improvement was to replace it by the GNU APL native primitive uniq (∪). in addition, a heuristic is used to avoid calling uniq when its effects are likely minor. Also, specializing some functions for untimed nets greatly improved times for these nets.
After these optimizations, we now have times:
-
l6000: 4.65 (6000 markings)
trains3e: 11.7 (3101 classes)
mickey5: 113 (4321 classes)
As can be seen, tina V1.1 significantly improves V1.0 times. But it still remains orders of magnitude behind the subsequent versions 2.X.Y written in SML, themselves way slower than the latest highly optimized 3.X.Y versions also in SML. One of the reasons is that the original APL lacked support for "irregular" data structures like trees, what makes difficult to implement efficiently the state graph and its operations. Beyond a few thousand state classes or markings, TINA V1 becomes unsuitably slow. But it was designed as a proof of concept rather than an industrial tool, and it played well that role. The ideas introduced by TINA V1 are notably discussed in papers [1][26][22][2][27][3][5][23]
A short description of the encoding of state classes and state graphs is found in file data-structures of the V1.0 and V1.1 distributions.
Assets:
Usage
-
Use exactly as above V1.0.